哈希表
无论是数组还是链表,其对数据的查询表现都比较无力,要想知道一个元素是否在数组或链表中,只能从前向后挨个对比。在后续将会分析的二叉排序树中,还会将数据排序以进行二分查找,将时间复杂度从O(n)降低到O(lg n)。
出现这个问题的根源在于,我们没有办法直接根据一个元素找到它存储的位置,那有没有办法消除这个对比的过程呢?哈希表就是解决查询问题的一种方案。
什么是哈希表
通俗来讲,哈希表是通过关键字key来获取数据的一种数据结构。它把关键字映射成表中的位置来获取元素,这种映射称为hash函数。
因为不同的key类型不一样,可能是int,可能是string…但内存地址不会以这些对象也寻址,它会通过hash算法将其转换成int从而完成数据的存储。hash函数需要保证的是对于相同的key,其计算结果总是相同的。
这个过程类似查字典,如果要查一个字,我们不会从第一页到最后一页挨着看,这将需要很长的时间,而是根据其发音先在拼音表中找到对应的页数,直接定位到对应的页即可。当然,由于有许多发音一致的汉字,所以我们可能依然需要逐个对比,但这复杂度就小太多了。
哈希表的过程就和上述例子一样,我们通过key经过hash算法直接定位其位置。然而类似于许多发音一致的,也就是有许多的key通过hash定位的结果是一样,那么这就是hash碰撞。
如何解决hash碰撞
目前比较通用的方法就是使用数组加链表去处理,先看一张图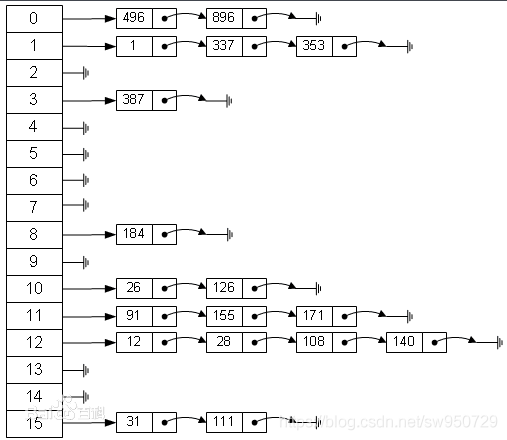
然后举个简单的例子:
hashmap是数组和链表的结合,它拥有这两种特性。怎么说呢?举个例子,一个学校有不同年级,不同年级有不同班级,不同班级有不同的学生。hashmap里面包含了一个数组,entry包装对象,而entry里面包含了k,v,next。
对next有似曾相识的感觉?打个比方。用年级对应k,班级对应v。而同一个年级,同一个班级,有不同的学生,对于这个学生,就是通过next来查询的。在后续文章中我们会对其进行详尽的分析。
哈希表的优缺点
哈希表是一种优化存储的思想,具体存储元素的依然是其他的数据结构。设计良好的哈希表,能同时兼备数组和链表的优点,它能在插入和查找时都具备良好的性能。然而设计不好的哈希表,有可能会出现较多的哈希碰撞,导致链表过长,从而哈希表会更像一个链表。还有当数据量很大时,为防止链表过长,就需要对数组进行扩容,这时就涉及到了数组的拷贝,其对性能的影响也很严重,所以需要提前对可能的情况有良好的预测,才能真正发挥哈希表的优势。
 微信
微信 支付宝
支付宝




